introduction au machine learning
Dans cet article nous verrons la base du machine learning, ces grandes catégories et l'impact de cette nouvelle technologie sur le monde.
MACHINE LEARNING
Leonard Docquier
5/31/20258 min read
Qu'est-ce que le Machine Learning ? Guide complet pour comprendre les bases
Imaginez un système capable d'apprendre de ses erreurs, de s'améliorer avec l'expérience et de prendre des décisions de plus en plus précises sans qu'on lui ait explicitement enseigné chaque situation possible. C'est exactement le principe du Machine Learning, une technologie qui révolutionne notre façon d'aborder les problèmes complexes et qui se cache derrière de nombreuses applications que nous utilisons quotidiennement.
Comprendre le Machine Learning : définition et fonctionnement
Le Machine Learning, ou apprentissage automatique en français, représente une méthode révolutionnaire qui permet aux ordinateurs d'apprendre et de s'améliorer automatiquement grâce à l'expérience, sans être programmés de manière explicite pour chaque tâche spécifique. Pour bien comprendre ce concept, pensez à la façon dont un enfant apprend à reconnaître les animaux : après avoir vu suffisamment d'exemples de chats et de chiens, il développe naturellement la capacité de distinguer ces deux espèces, même face à des animaux qu'il n'a jamais vus auparavant.
Le Machine Learning fonctionne selon le même principe fondamental. Il repose sur des modèles mathématiques sophistiqués qui analysent des données, identifient des patterns récurrents et construisent progressivement une compréhension du monde à partir de ces observations. Ces modèles s'enrichissent et s'affinent au fur et à mesure qu'ils sont exposés à de nouvelles informations, développant ainsi une forme d'intelligence adaptative.
Il est important de comprendre que le Machine Learning constitue un sous-domaine de l'intelligence artificielle, travaillant en étroite collaboration avec la science des données. Alors que l'IA englobe tous les systèmes capables de simuler l'intelligence humaine, le Machine Learning se concentre spécifiquement sur la capacité d'apprentissage à partir de données. Cette spécialisation en fait un outil particulièrement puissant pour résoudre des problèmes où les règles traditionnelles de programmation atteignent leurs limites.
Pourquoi le Machine Learning transforme-t-il notre monde ?
L'importance croissante du Machine Learning dans notre société s'explique par sa capacité unique à automatiser des tâches complexes tout en améliorant constamment leur efficacité. Cette technologie excelle dans la création de prédictions personnalisées et l'optimisation de processus qui nécessiteraient normalement une intervention humaine constante.
Les applications concrètes du Machine Learning touchent pratiquement tous les aspects de notre vie quotidienne. Lorsque vous demandez quelque chose à votre assistant vocal, celui-ci utilise des algorithmes de Machine Learning pour comprendre votre voix et interpréter vos intentions. Dans le domaine médical, ces systèmes analysent des milliers d'images radiologiques pour aider les médecins à détecter précocement certaines maladies. Le secteur financier s'appuie sur le Machine Learning pour évaluer les risques de crédit, détecter les fraudes et optimiser les stratégies d'investissement. Même les moteurs de recherche que nous utilisons quotidiennement dépendent entièrement d'algorithmes d'apprentissage automatique pour nous proposer les résultats les plus pertinents.
Les grandes catégories du Machine Learning expliquées
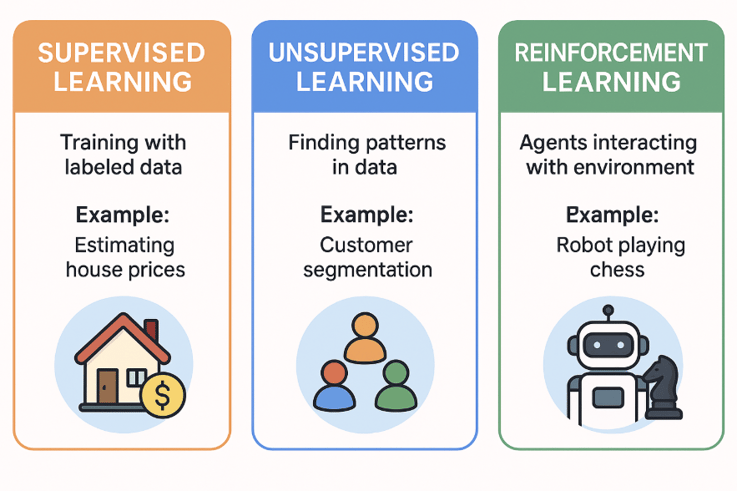
Pour mieux comprendre comment fonctionne le Machine Learning, il est essentiel de connaître ses trois grandes approches, chacune adaptée à des types de problèmes spécifiques.
L'apprentissage supervisé représente probablement l'approche la plus intuitive du Machine Learning. Dans cette méthode, nous fournissons au système des exemples complets où nous connaissons déjà les bonnes réponses. C'est comme enseigner à un étudiant en lui montrant des problèmes résolus : le système apprend à identifier les patterns qui mènent aux bonnes solutions. Cette approche excelle dans les tâches de prédiction, que ce soit pour estimer le prix d'une maison en fonction de ses caractéristiques ou pour déterminer si un email est du spam ou non.
L'apprentissage non supervisé adopte une approche radicalement différente. Ici, nous donnons au système des données sans lui indiquer les réponses attendues, un peu comme demander à quelqu'un d'organiser une bibliothèque sans lui donner de système de classification préétabli. Le système doit découvrir par lui-même les structures cachées et les groupes naturels présents dans les données. Cette méthode s'avère particulièrement précieuse pour la segmentation de clientèle, où l'algorithme peut identifier des groupes de consommateurs ayant des comportements similaires, ou pour la détection d'anomalies dans des systèmes complexes.
L'apprentissage par renforcement s'inspire directement de la psychologie comportementale. Le système apprend en expérimentant différentes actions et en recevant des récompenses ou des pénalités selon la qualité de ses choix. Cette approche ressemble beaucoup à la façon dont nous apprenons à jouer à un jeu vidéo : nous essayons différentes stratégies, observons les résultats, et ajustons progressivement notre comportement pour maximiser notre score. Les applications les plus spectaculaires de cette méthode incluent la conduite autonome, où les véhicules apprennent à naviguer en sécurité, et les systèmes de jeu comme AlphaGo qui ont révolutionné des domaines entiers.
Il existe également des approches hybrides comme l'apprentissage semi-supervisé, qui combine des données étiquetées et non étiquetées, et l'apprentissage profond (deep learning), qui utilise des réseaux de neurones artificiels complexes pour traiter des données très sophistiquées comme les images ou le langage naturel.


Focus sur la régression linéaire : prédire des valeurs continues
La régression linéaire constitue l'un des outils les plus fondamentaux et les plus élégants du Machine Learning. Son principe repose sur l'identification d'une relation linéaire entre différentes variables pour prédire des valeurs continues. Imaginez que vous voulez estimer le prix d'une maison : vous savez intuitivement que des facteurs comme la superficie, le nombre de chambres ou la localisation influencent le prix. La régression linéaire formalise cette intuition en créant une équation mathématique qui pondère l'importance de chaque facteur.
Le processus d'apprentissage utilise une fonction de coût, généralement l'erreur quadratique moyenne (MSE), qui mesure la différence entre les prédictions du modèle et les valeurs réelles. L'algorithme ajuste progressivement les paramètres du modèle pour minimiser cette erreur, un peu comme un archer qui ajuste sa visée après chaque tir pour se rapprocher du centre de la cible.
La régression linéaire repose sur plusieurs hypothèses importantes : la relation entre les variables doit être approximativement linéaire, les erreurs doivent suivre une distribution normale, et les observations doivent être indépendantes les unes des autres. Comprendre ces hypothèses est crucial pour appliquer correctement cette technique et interpréter ses résultats.
La régression logistique : prédire des probabilités et catégories
Malgré son nom qui peut prêter à confusion, la régression logistique ne prédit pas des valeurs continues mais des probabilités et des catégories. Cette technique transforme le problème de classification en problème de probabilité grâce à la fonction sigmoïde, une courbe mathématique élégante qui compresse toute valeur entre 0 et 1.
La beauté de la régression logistique réside dans sa capacité à fournir non seulement une prédiction (par exemple, "cet email est du spam") mais aussi une mesure de confiance (par exemple, "je suis sûr à 85% que cet email est du spam"). Cette information de confiance s'avère précieuse dans de nombreuses applications pratiques.
Les cas d'usage de la régression logistique sont nombreux et variés : détection de fraude bancaire, prédiction de maladies en médecine, analyse du churn (départ des clients), et bien d'autres. Sa simplicité relative et son interprétabilité en font un choix privilégié quand il est important de comprendre pourquoi le modèle prend certaines décisions.
Classification : attribuer intelligemment des catégories
La classification représente l'une des tâches les plus courantes du Machine Learning. Son objectif consiste à attribuer automatiquement une catégorie ou une étiquette à chaque donnée d'entrée. Cette capacité trouve des applications dans d'innombrables domaines de notre vie quotidienne.
La classification peut prendre plusieurs formes selon le nombre de catégories possibles. La classification binaire distingue entre deux options (spam ou non-spam, malade ou sain), la classification multiclasse gère plusieurs catégories mutuellement exclusives (chien, chat, oiseau), tandis que la classification multi-label permet à un même élément d'appartenir simultanément à plusieurs catégories (un film peut être à la fois "action" et "science-fiction").
Les algorithmes de classification incluent des méthodes variées comme K-NN (k plus proches voisins), qui classe selon la similarité avec les exemples les plus proches, SVM (machines à vecteurs de support), qui trouve la meilleure frontière entre les classes, Naïve Bayes, qui utilise des probabilités conditionnelles, et les arbres de décision, qui créent des règles hiérarchiques facilement interprétables.
Conseils pratiques pour maîtriser le Machine Learning
L'apprentissage du Machine Learning nécessite une approche progressive et méthodique. Commencez toujours par des exemples concrets et tangibles avant d'aborder les concepts théoriques abstraits. La visualisation joue un rôle crucial : utilisez des graphiques et des diagrammes pour représenter les concepts et les résultats. Cette approche visuelle aide énormément à développer une intuition solide.
Évitez deux écueils courants : le jargon technique excessif qui peut décourager les débutants, et la sursimplification qui peut conduire à des malentendus. Trouvez le juste équilibre en expliquant les concepts techniques avec des analogies du monde réel tout en préservant leur précision scientifique.
La préparation des données représente souvent 80% du travail en Machine Learning. Des données de qualité constituent la fondation de tout projet réussi. Investissez du temps dans le nettoyage, la transformation et la validation de vos données avant même de choisir un algorithme.
Outils et ressources pour la pratique
Python s'est imposé comme le langage de référence pour le Machine Learning, grâce à sa syntaxe claire et son écosystème riche. R reste également populaire, particulièrement dans les domaines statistiques et la recherche académique.
L'écosystème Python offre des bibliothèques spécialisées pour chaque aspect du Machine Learning. Pandas simplifie la manipulation des données, NumPy fournit les opérations mathématiques fondamentales, et Scikit-learn propose une interface unifiée pour la plupart des algorithmes classiques. Pour les projets plus avancés, TensorFlow, Keras et PyTorch permettent de construire des modèles d'apprentissage profond sophistiqués.
Ces outils démocratisent l'accès au Machine Learning en fournissant des implémentations optimisées et bien documentées des algorithmes les plus importants. Ils permettent aux praticiens de se concentrer sur la résolution de problèmes plutôt que sur l'implémentation de détails techniques complexes.
Construire l'avenir avec le Machine Learning
Le Machine Learning représente bien plus qu'une simple technologie : c'est un paradigme qui transforme notre façon d'aborder les problèmes complexes. Sa capacité à créer des modèles adaptatifs et évolutifs ouvre des possibilités jusqu'alors inimaginables dans de nombreux domaines.
Cependant, la réussite d'un projet de Machine Learning dépend de facteurs cruciaux : la qualité et la pertinence des données, une formulation claire du problème à résoudre, et des choix méthodologiques rigoureux. Ces éléments, plus que la sophistication des algorithmes, déterminent souvent le succès ou l'échec d'une application.
En maîtrisant ces concepts fondamentaux et en adoptant une approche méthodique, vous disposerez des outils nécessaires pour explorer ce domaine fascinant et contribuer à façonner l'avenir de nos interactions avec la technologie. Le Machine Learning n'est plus réservé aux experts : il devient progressivement accessible à tous ceux qui souhaitent résoudre des problèmes de manière innovante et efficace.